Password-less Authentication — Speed up Sign-in with FaceID/TouchID
August 6, 2023 Leave a comment
Many banking apps have introduced an experience to allow you to login with just a FaceID or TouchID. The experience works as follows:
- After you successfully login, the app asks you if you want to use FaceID/TouchID to speed up login in the future, like this TaxCaddy interface:
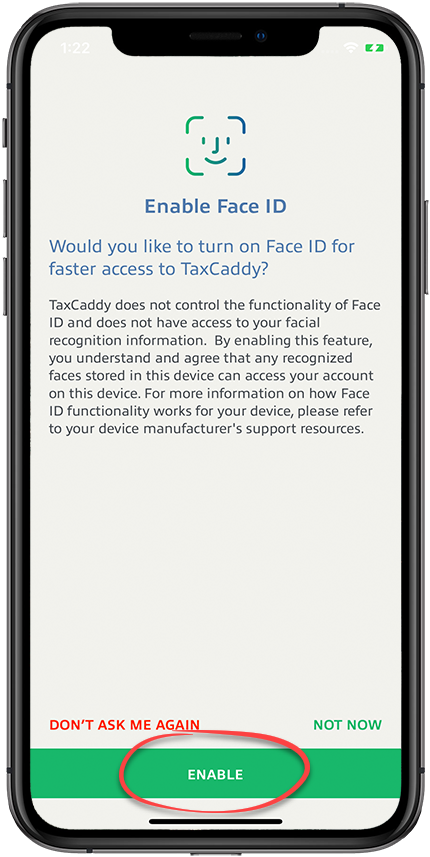
2. When you consent, a system prompt pops up to confirm FaceID/TouchID enrollment.
3. When you login in the future, a FaceID/TouchID prompt pops up automatically, and if the scan is successful, you are logged in. No more passwords, no more OTP code through SMS.
How is this implemented under the hood? Is it secure? In this post, I will show you some sample code, and explain how it works.
How it works
While the login is a password-less experience, under the hood, it is actually implemented with a password like mechanism.
In step 2 above, when you enroll in FaceID/TouchID, a secret is generated. The secret is both stored locally on your device (guarded by the FaceID/TouchID), and also stored on the server.
In step 3 above, when you scan your FaceID/TouchID, it unlocks the saved secret, then it sends the secret to the server for comparison. If the server confirms that the secret matches, you are allowed in.
Even though it is a password-less experience, and you are not directly aware of the secret, the secret serves the same purpose as a regular password.
Code sample
There are at least a couple of ways of implementing this logic in iOS. You could use the Keychain API to store the secret and attach an access policy generated by the SecAccessControlCreateWithFlags API. Since you can easily find a sample code for that, I will show a different, and yet simpler way to leverage the LARight API, by leveraging the LASecret field that is stored as part of the LAPersistedRight object.
In step 2 above, we first generate a long random secret which is hard for a human to remember. Then, use iOS’s LARight API to save the secret to the Keychain on the device locally, as follows:
// retrieve a Secret from server, and save locally
func saveSecret() async throws -> Data {
// let server generate a random unique secret
let secret : Data = getRandomSecretFromServer()
// initialize LARight
let right = LARight()
// in case there were secret generated before, clean up before saving a new secret
try await LARightStore.shared.removeRight(forIdentifier: keyIdentifier)
// save a new PersistedRight with the secret
let persistedRight = try await LARightStore.shared.saveRight(right, identifier: keyIdentifier, secret: secret)
try await persistedRight.authorize(localizedReason: "Saving secret...")
// return the secret in case the UI wants to display a hash
return try await persistedRight.secret.rawData
}In step 3, when we need to verify the secret with the server, we call the following function:
func verifySecret() -> Bool {
// retrieve the previously saved secret from Keychain
let persistedRight = try await LARightStore.shared.right(forIdentifier: keyIdentifier)
try await persistedRight.authorize(localizedReason: "Authenticating...")
let localSecret = try await persistedRight.secret.rawData
// verify with the server
return verifySecretWithServer(localSecret)
}Is it secure? Should I implement FIDO2 instead?
This FaceID/TouchID mechanism described above is stronger in its security guarantee than a password. It is phishing-proof because the secret is not humanly readable, thus there is nothing to leak in a social-engineering attack. It can also be considered as 2FA (Two Factor Authentication), because it verifies both something you own (your device where the secret is stored) and something you are (your face or touch scan).
However, this FaceID/TouchID mechanism is weaker than the FIDO2 protocol, because it is not server-hacking proof. The secret stored on the server could be leaked if the server is comprised. In contrast, FIDO2 is server-hacking proof, because it only stores a public key on the server, and a hacker cannot gain any advantage even if they gain access to the public key.
Summary
I have shown you some simple code on how to implement a FaceID/TouchID password-less experience. If you are not ready to adopt FIDO2 yet, this is a simple way to boost your app’s security. Compared to FIDO2, this solution offers a simpler account recovery experience. If the user loses their device, the server still has the secret, which can be used to bootstrap a new device.
Note: this article is also posted at medium as Password-less Authentication — Speed up Sign-in with FaceID/TouchID.